
AI Is Enhancing Speech to Text*
Turning Spoken Words into Reliable Business Results
You’re on the phone trying to fix a billing issue. You speak clearly: “I need to speak to a representative.” The automated system comes back with, “I’m sorry, I didn’t understand. Did you say ‘account balance’? Please say yes or press one.”
Or you’re driving and tell your phone, “Call Mom,” only to get connected to Tom. Or you dictate a quick note in a noisy office and the text comes out as nonsense.
These voice system frustrations are still fresh in many people’s minds. Yet the technology has made real progress. Today’s speech recognition turns spoken words into clean, usable text that actually supports business operations — from customer service calls to internal note-taking and team collaboration. Here’s how the process works now, how it got here, and what it delivers in practice.
How Modern Speech Recognition Works
The core approach is straightforward: one unified system takes raw sound and produces text without the old mix of separate rules and models. It works probabilistically — it calculates what words are most likely based on patterns learned from huge amounts of real audio, then selects the best match.
The flow breaks down into these practical steps:
1. Capture and Clean the Sound
The microphone records the audio wave. The system immediately cuts background noise, removes echoes, and figures out exactly when someone is speaking — even in a moving car or busy room.

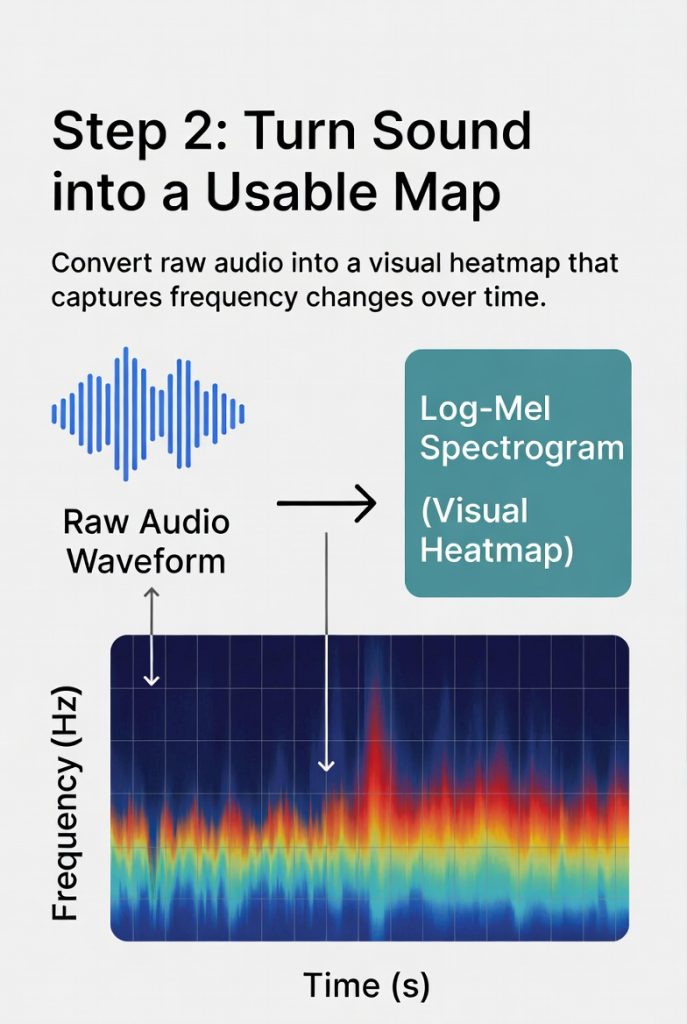
2. Turn Sound into a Usable Map
The audio becomes a visual heatmap of frequencies over time. This format lets the system spot the patterns that match human speech.
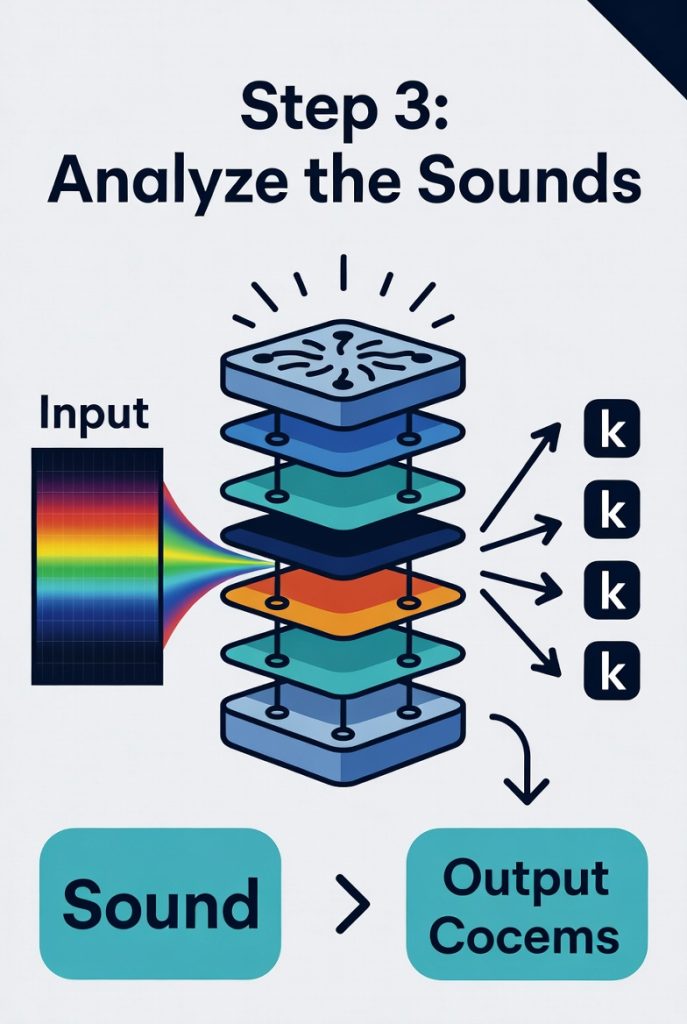
3. Analyze the Sounds
A transformer-style network examines the map. It identifies basic sound units (like the “k” in “cat”) while keeping track of longer patterns and context.
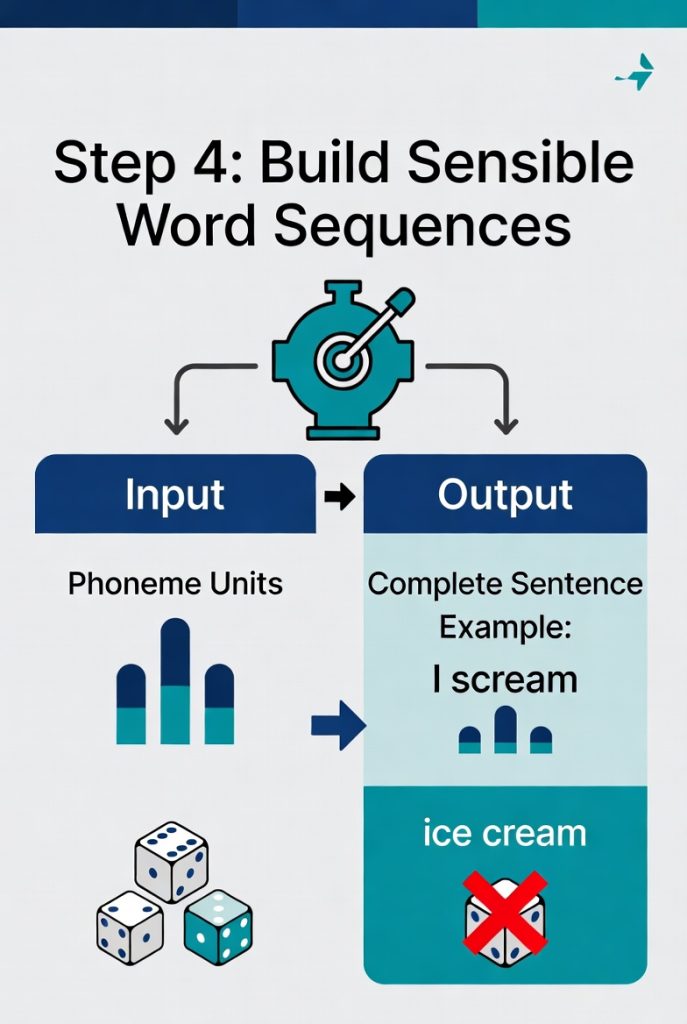
4. Build Sensible Word Sequences
The system predicts full words and sentences that fit grammar and real meaning. It weighs probabilities — for example, “I scream” makes more sense in most sentences than the identical-sounding “ice cream.”
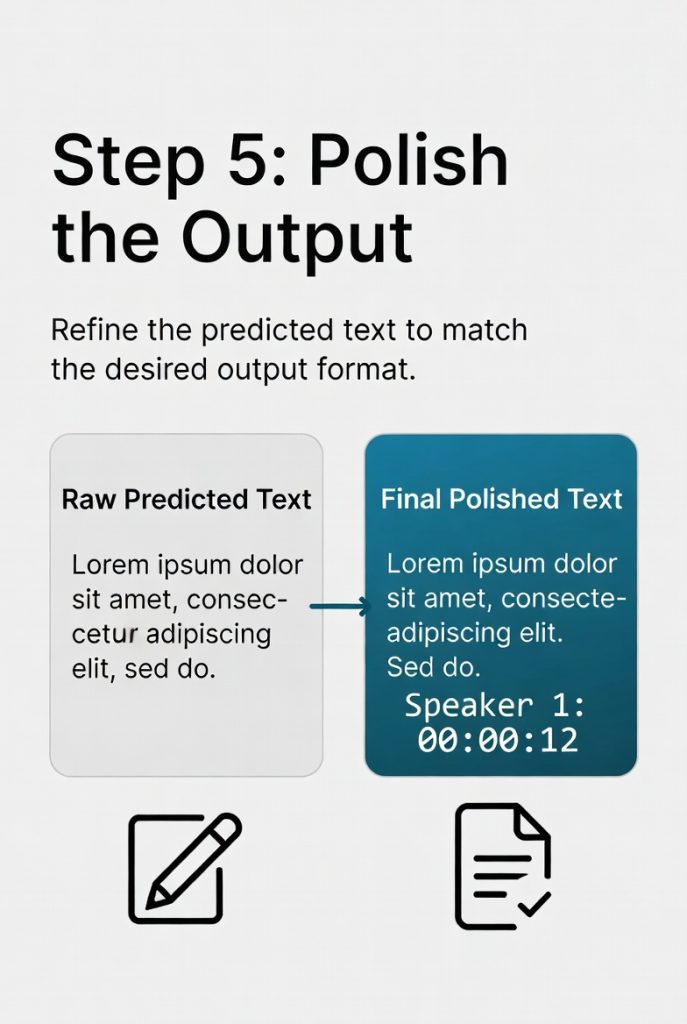
5. Polish the Output
It adds punctuation, capital letters, speaker labels, and time stamps automatically. The result is ready-to-use text.
All of this runs in a single trained model. No more piecing together separate parts like the older methods required.
How the Technology Evolved
Speech recognition has followed a clear path of improvement over seventy years.
Early systems in the 1950s and 1960s were rule-based and very limited. They recognized digits or a handful of words only under perfect conditions and required careful, slow speaking.
From the 1970s into the 2000s, statistical models took over. Projects expanded vocabulary and began handling full sentences. These systems improved accuracy but still needed individual training and struggled with noise or different accents.
The 2010s brought deep learning networks that replaced the old statistical approaches. Voice assistants became widely available, worked for most speakers, and handled real-world conditions much better.
In recent years the biggest gains have come from end-to-end models trained on massive collections of audio. These systems now manage accents, background noise, and conversations across languages with far greater consistency. The latest technology delivers solid, dependable performance where it matters most in business operations.
The End Result: Spoken Words Turned into Actionable Text
The output is clear, punctuated text with time stamps and speaker identification when needed. You can edit it, search it, or feed it straight into other systems for follow-up action.
Leading approaches today achieve strong accuracy in everyday situations — meetings, customer calls, field notes. Doctors capture visit details without stopping their work. Drivers issue commands safely. Global teams transcribe discussions across languages in real time.
The real value shows up in operations: fewer errors, faster follow-through, and less time wasted repeating or correcting information. As the technology continues to improve with current deep-learning methods, speech recognition is becoming standard infrastructure that lets people communicate naturally while the system handles the rest.
It is a clear example of artificial intelligence meeting real work where it happens — through voice — and turning that input into reliable, usable results.
*This article was researched and composed with the help of GROK AI!